Back story
Hi, please bear with me on this long blog post. There is lots to explain and the topic is not a easy one.
In the last 3 months my team and I struggled with a problem in our SOA solution. We have a business requirement that requires that we need to service 250 concurrent connections to a WCF service in under 3 seconds but our service performed so badly when placed under load that we were miles off the target. What made things even more dubious were that the test server was not showing any major CPU usage, so we knew we did not hit the hardware limits.
The 250 concurrent connections represents 1% of the actual user base and the 3 seconds comes from a customer SLA requirement.
Originally the development of this service and its use case was not the responsibility of the Core team but because of the poor performance of the service it was deemed the responsibility of the Core team to find the problem.
When we executed our one service operation with a single user it performed acceptable with a time of 0.710 seconds but when placed under load the code buckled and returned results in 84.4 seconds.
We set out and to create a sterile testing platform thinking that the problem was with our setup of the WCF services. As the hardware did not show any signs of load when we placed the services under load originally – there must be a bottleneck somewhere. The testing platform would test the different bindings, operation types, service configurations and deployment options. The WCF test infrastructure was not specific to any product, it was a product agnostic only testing the WCF infrastructure to find which setup would give us the best performance. This exercise took us about 6 weeks. We played with throttles, concurrency modes IO Threads but the results from the tests gave us favourable results in throughput and load. – The problem was not with our WCF Infrastructure – we where looking in the wrong place.
Problem Found
We took the product code and started disabling portion of the code. Eventually after much investigation we identified that the problem was with the Entity Framework code and we set off trying to optimize our queries as our first thought was that we wrote some bad linq queries but no matter what we did the speed under load did not improve. Eventually we said – wait, lets remove all the queries and business logic and put in its place a simple query just as a test.
This simple EF query would do a single select statement on a single table that contained 3 rows and 11 columns and it would filter on a primary key. We placed the same code under load and was shocked to get a result of 5 seconds.
Until this point we were using Entity Framework (EF) and no matter what we did we could not get it to perform under load. Eventually a call was made to substitute the EF calls with stored procs, just to see what the speed increase would be. This change took us from 84.4 seconds to 4.25 seconds under load. I should point out that at this point we did not know why EF was slow we simply new that it was. As in most software companies one is not given endless time to find out why – the problem had to be fixed – NOW.
While doing the investigation i found a comment i made towards post Stored procedures are bad, m’kay? on Frans Bouma’s blog.
I am a firm believer that you use the technology that will be the easiest to maintain in the long run for a specific job NOT the technology that will give the best results necessarily. Maybe i am wrong, but as a developer i will be the one doing the work in the end.
For example Assembler and C++ is faster executing code than .Net CRL – Why don’t we all use it then? Because it is harder to maintain and takes longer to do the job, So it is NOT the best tool for the job. Now why should communication to a database be any different?
Looking at the comment that I made 12 years ago on Frans Boumas blog i have to disagree slightly with myself. I will say:
I am a firm believer that you use the technology that will best fit the specific use case; with preference given to the option that will make it the easiest to maintain.
With this specific use case we found that high performance was a mandate and “ease of maintenance” might have to be sacrificed to achieve this business requirement.
One often finds that high performance and maintainability are mutually exclusive options. High performance usually means you are using a old technology closer to the hardware layer, which in essence does less but are harder to maintain. See Fundamentals of Computer Systems: Generations of programming language
The ORM investigation
The unexplained sluggishness of Entity framework resulted in a rapid investigation into different ORMs as we knew the developers would not be happy with the idea of having to maintain stored procedures, even though stored procedures achieved the desired performance result.
Object–relational mapping (ORM, O/RM, and O/R mapping tool) in computer science is a programming technique for converting data between incompatible type systems in object-oriented programming languages. This creates, in effect, a “virtual object database” that can be used from within the programming language
https://en.wikipedia.org/wiki/Object-relational_mapping
The high level requirements for the replacement ORM were:
- It must be fast.
- Easy to understand out of the box.
- Easy to maintain.
- Similar syntax to Entity framework would be advantages.
- Strong typed.
- Be as feature rich as possible compare to Entity Framework.
We were willing to sacrifice some performance, within reason, if we could gain some maintainability and still be able to execute within the required time.
We identified NHibernate, LLBLGen Pro V4, Linq to SQL and Dapper. Dapper is a lite ORM and was included for performance reasons even though we knew it lacked the feature richness of Entity framework.
LLBLGen was my personal favourite to replace Entity framework with as i have worked with it in the past and knew it was fast. For every test LLBLGen would have 3 variations; Adapter, Self Servicing and Linq. I contacted Frans Bouma and he shared some of his personal ORM bench testing results with me. Thank you very much for you assistance here Frans. 😉
The Load Test framework
We decided that the tests that were about to write would be ran against ADO.NET with inline sql to give us a base to compare too and would consist out of a throughput test and a load test. All tests would be ran against the same database. As the ORM’s failed to meet our requirements they would be eliminated from the possible candidates.
The following tests where lined up. Each of the 250 simulated users would do a :
1. Single record select from a single table and transform into Object.
2. Simple Inner join select from two tables and transform into Object.
3. Complex query consisting out of a Union with nested selects and transform into Object.
4. Multi simple record select execution within a single service call and transform into Object.
5. Multi Complex queries within a single service call both transforming the data to Objects.
Please note there is a difference between load testing and throughput testing. Throughput testing is the result of calling the same code over and over and measuring the avg response times for a single user over a duration. Load testing creates virtual users and simulates load by getting each user to call the same code over and over while maintaining the user load over a duration.
The Microsoft load testing framework consisted out 2 Agents and 1 controller setup on three i7 8 core machines with 8GB of ram and SSD Hard drives each, Te machines were placed on their own network running at 1Gbit.
Below is an example of what the dash board of the load testing tool looks like.
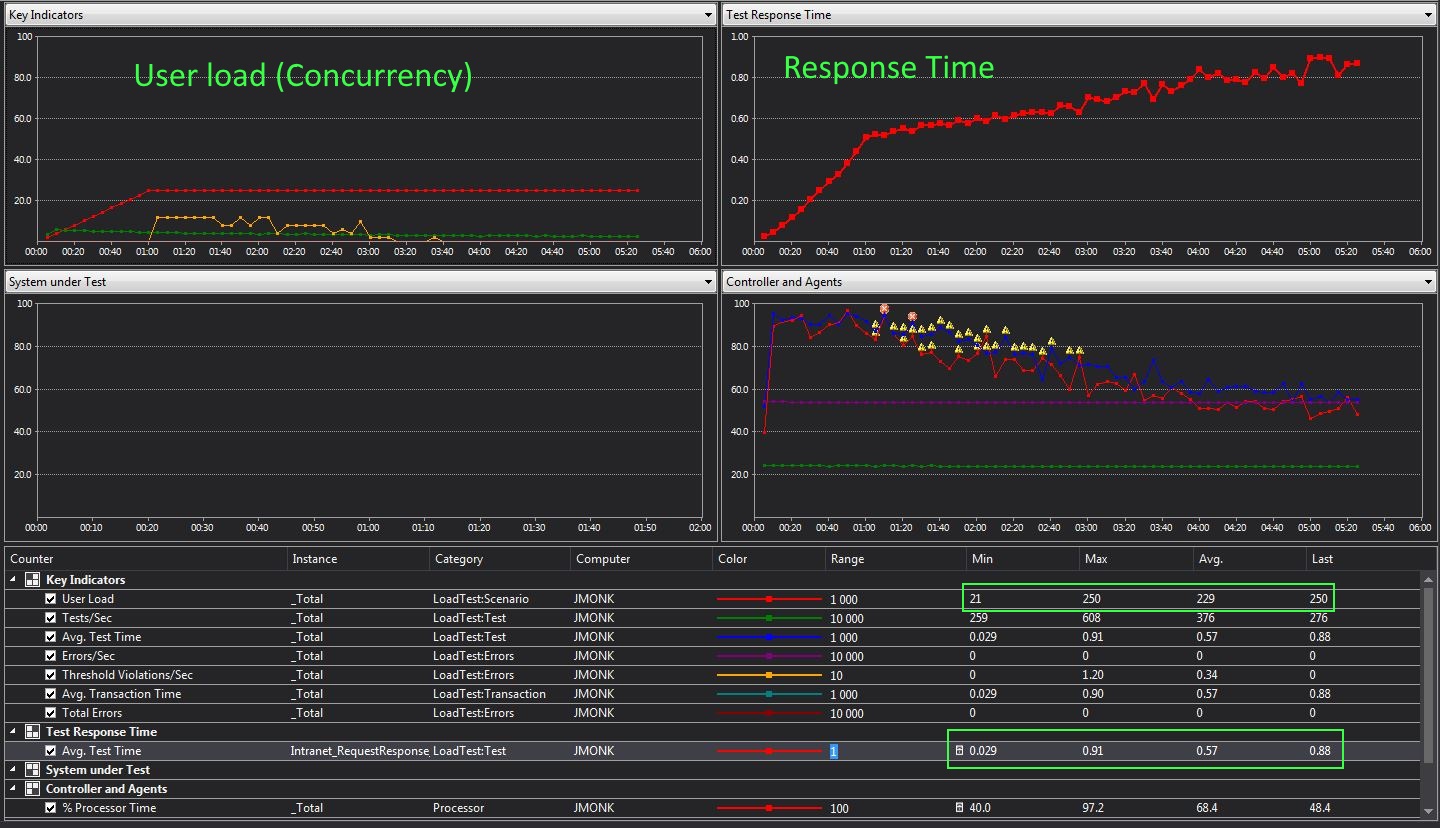
Image above showing LLBLGen Adapter under load.
ADO.Net was setup to allow 250 sql connections in the pool.
The WCF service were setup to use per call services in a single hosting process running over net.tcp binding with a throttle of 250 and 1000 available threads.
Disclaimer: Please note that the results below was gathered over a 3 week period. The developers that wrote the tests and the testers that tested the products were not experts in any of the products. During this period each of the products had to be installed and learned. Thus it is possible that with additional time and knowledge and tweaking products could have been made to perform better. We simply did not have this luxury. When a developer was stuck an attempt was made to contact support to try and ensure the best results.
Test Results
Throughput test results.
Throughput testing is the result of calling the same code over and over and measuring the avg response times for a single user over a duration.
Single record select.
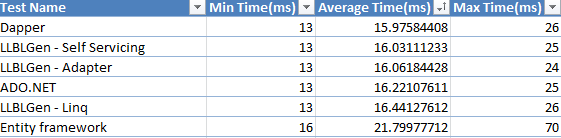
Simple join on primary keys between 2 tables.
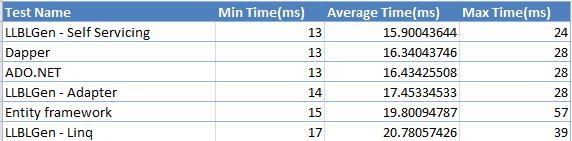
Load test results
Load testing creates virtual users and simulates load by getting each user to call the same code over and over while maintaining the user load over a duration.Single record select from a single table results.

Things to note from this result:
- As can be seen from the initial results we decided to eliminated NHibernate from the list of considered ORMs. It performed very bad and it might be in part due to our understanding of it but no additional time could be committed to it.
- Entity Framework did perform slower than the other ORMS but not as noticeable as it was within our product.
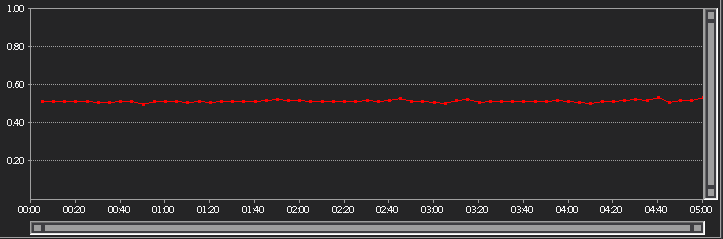
- ADO.Net, Dapper and LLBLGen Self Servicing showed no degradation in performance while under load and stayed consistent throughout.(Image for Dapper)
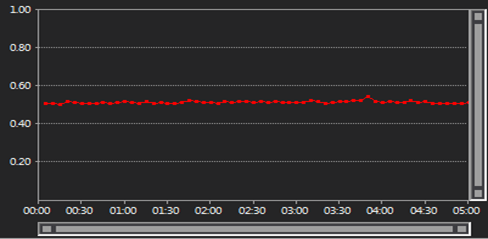
(Image for LLBLGen Self servicing)
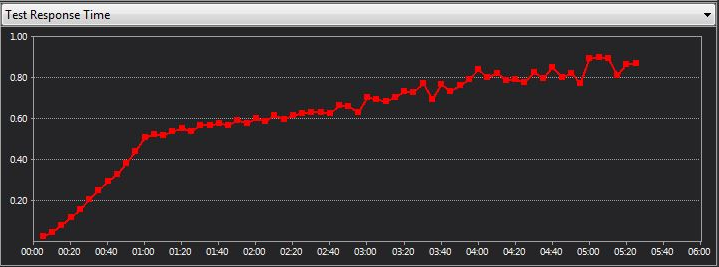
- Entity framework response times degraded with time, the longer the tests ran the slower it got even after the max load was achieved.
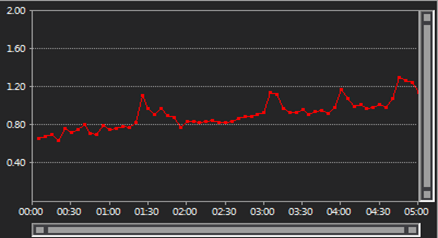
- LLBLGen with Adapter also showed a degradation in performance over time but not to the same extend as Entity framework.
Simple Inner join select from two tables results.
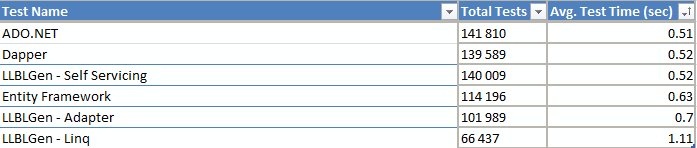
Things to note from this result:
- Adapter and Linq joins with LLBLGen came in last in this test run but Self servicing performed on par with dapper. This was a surprise as we expected Adapter pattern to be fastest. This could not be explained. The query was sent to Frans for review.
Code snippets
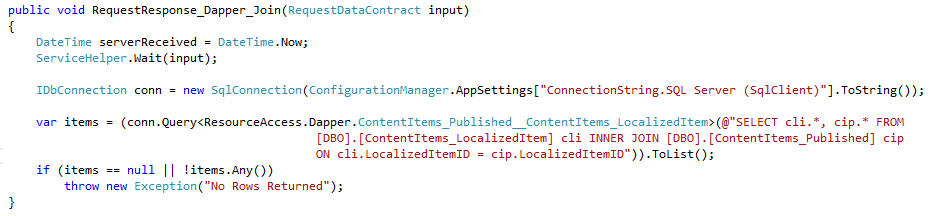
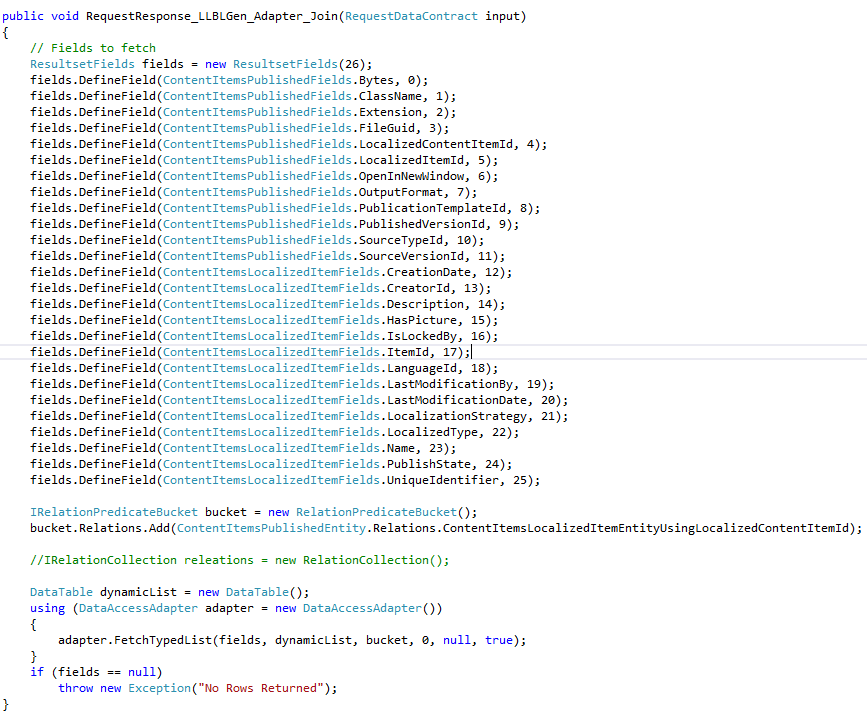
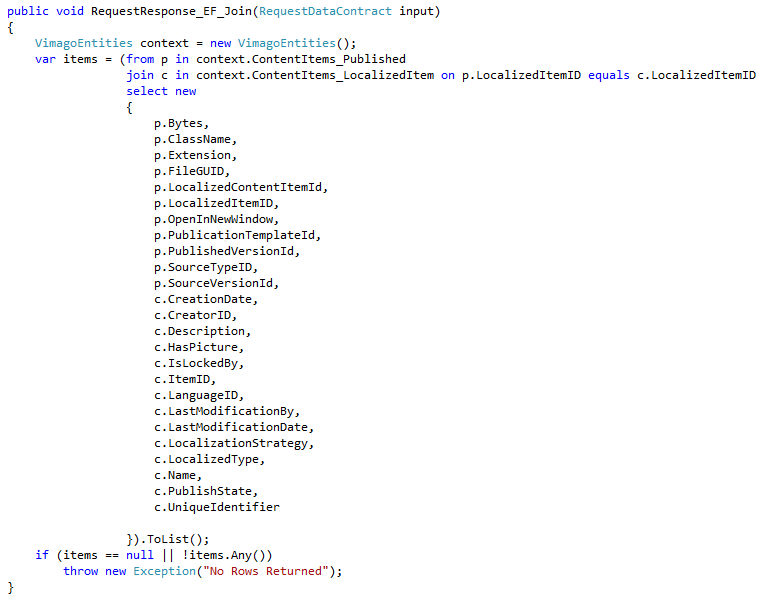
Due to the surprise with the results from the last test I decided to show the code – for incase we did something wrong. Josh and myself discussed the queries with Frans from LLBLGen. Self Servicing should be slower than Adapter, so Frans felt something else was going wrong.
Dapper
LLBLGen – Self servicing

LLBLGen – Adapter
Entity Framework
Complex query consisting out of a Union with nested selects results.

Things to note from this result:
- Dapper perfromed faster than ADO.Net in this test but it is so close that i would not look too deeply into the result. Bottomline is that Dapper is at least just as fast as ADO.Net.
- You will notice that LLBLGen has been eliminated from the test run. This was due to it not supporting Unions and nested selects. The replacement ORM had to have a similar feature set as Entity framework to allow developers to quickly map the syntax from the EF over to the replacement ORM. We had existing queries written in Entity framework that were using Unions and nested selects and unfortunately it was a requirement. So although self servicing did perform well enough the feature limitation eliminated it.
- Management made a call at to eliminate Entity framework from this test run.
As i pointed out before none of the tests that we did showed the degradation in performance in Entity framework as we saw within the product. So eventually we convinced management that before we go the exercise in replacing EF we should investigate more. We were allowed to run one additional test. We decided to execute multiple statements within a single operation.
Multi simple record select execution within a single service call results.

Things to note from this result:
- Immediately one can see that when multiple statements are being executed Entity framework doubled its response time vs the other technologies.
Conclusion
Software does weird things under load. At this stage of our investigation we have not managed to identify why Entity framework was so slow and we might never know.
Business was satisfied with the Stored procedure solution. They were happy to accept the maintenance overhead and Dapper was accepted as the solution for all use cases that required high performance while Entity framework will remain the defacto ORM in the organisation for low concurrency areas in the software.
Dapper was fastest but has a limited feature set.
LLBLGen is fast, feature rich but currently has no union or nested query support.
Entity framework is slow but feature rich.
I hope that our investigation into some of the ORM’s on the market help others.
Special thanks to my team mate Josh Monk who wrote and performed all the tests, I need to thank him for giving me the results so i could share it here with you all.
(I wrote LLBLGen Pro)
As I told your collegue, the queries aren’t the same, selfservicing uses an entity fetch, adapter uses a dynamic list fetch using a datatable fetch. The selfservicing query returns less data than the adapter query. In v5 we optimized the projections a great deal though, and these queries are now faster than dapper. (See: https://github.com/FransBouma/RawDataAccessBencher)
The code for adapter uses the old low-level API too, which is something no-one uses these days anymore so it looks like our framework uses overly verbose code which is of course not the case anymore. 😉
Anyway, water under the bridge and irrelevant, because ‘union’ is a deal breaker and we don’t support that in our framework, so whatever we tweak on the framework, it won’t matter much. 🙂